



































































QUICK SUMMARY
Stitched-together multi-vendor APIs cause catastrophic latency delays when deployed over real-world carrier networks (killing your customer containment rates!).
This blog considers the stage-by-stage millisecond budget required to bypass public internet bottlenecks and silence-based endpoint detection.
Read on to discover the parallel streaming architecture and infrastructure footprint we use to hit a rock-solid sub-600ms p95 latency floor over Twilio SIP.
The problem with most voice AI advice on the internet is that it is tested over clean, isolated local development lines. When you deploy a real-world voice agent over the Public Switched Telephone Network (PSTN) using a Twilio SIP trunk, reality hits hard.
A pipeline that felt fast in your terminal suddenly shifts into an awkward 1.5-second to 2-second latency. Callers notice it instantly. They assume the bot didn’t hear them, start talking over it, get frustrated, and hang up.
Natural human conversation relies on a tight turn-taking window of 200ms to 500ms. If your automated voice stack breaches this latency ceiling, the timing of the entire interaction breaks down, destroying user containment rates.
To build a voice AI experience that actually scales, you have to find and eliminate latency at every single layer of the stack. In this blog, we break down the exact architectural blueprint used to drop end-to-end voice AI latency down to a crisp sub-600ms at the 95th percentile (p95) over Twilio.
What Is the Latency Budget of a Voice AI Agent Over Twilio SIP?
The true latency budget of a voice AI agent over Twilio SIP must remain under 600ms at p95 to ensure natural conversational flow. This total time accounts for every step from user silence to outbound playback.
If you run these steps purely in a linear sequence, your stack will fail. The secret to breaking the 600ms barrier is aggressively overlapping these processes while running your core infrastructure exactly where the telephony data lands.
Core Telephony Pipeline Stages
- Telephony Ingress & Signaling Handoff: Captures the raw carrier data packets streams directly from the SIP trunk edge.
- Voice Activity Detection (VAD): The computational layer that detects exactly when a user has completed their spoken thought.
- Speech-to-Text (STT) Transcription: Converts streaming raw binary audio data frames into textual data strings.
- LLM Generation Layer: The language model processes the input context window and generates text response tokens.
- Text-to-Speech (TTS) Synthesis: Converts text strings into high-fidelity audio payloads ready for network playback.
Latency Budget of a Voice AI Agent
| Pipeline Stage | Measured Target (p95) | Primary Bottleneck to Eliminate |
| Telephony Ingress | 40ms – 60ms | Cross-region internet routing and SIP signaling handoff overhead. |
| Turn Detection (VAD) | 80ms – 120ms | Waiting for hardcoded 500ms silence blocks instead of predictive endpointing. |
| Speech-to-Text | 100ms – 150ms | Single-turn transcript finalization delays over standard cloud WebSockets. |
| LLM Generation | 180ms – 240ms | Public API queuing and excessive prompt/context token bloat. |
| Text-to-Speech | 60ms – 100ms | Generating audio in large sentences instead of streaming raw byte buffers. |
| End-to-End Processing | Sub-600ms Total | Linear, stitched processing across separate multi-vendor clouds. |
What Causes the Most Latency In a Typical Twilio Voice AI Deployment?
Most of the latency in a Twilio voice deployment comes from multi-vendor cloud network hops and naive silence-based endpoint detection rather than the raw processing speed of your underlying language model.
The Multi-Vendor Cloud Hop
When a call hits Twilio, the raw audio is packed into packets and sent over the internet. If your application orchestration layer lives in AWS, your transcription engine runs on a third-party API, your LLM queries a public cloud endpoint, and your voice synthesis engine calls another external vendor. You are forcing that audio data to take a massive tour of external networks. Every single internet hop across different cloud providers adds 30ms to 100ms of unpreventable transport delay.
The Silence Trap (VAD)
Before your AI can think, it has to know the caller is done talking. Traditional Voice Activity Detection (VAD) handles this a bit weakly. It waits for a hardcoded block of absolute silence (usually 500ms) before it decides to pass the transcript to the LLM. This means you are throwing away half a second of your budget on dead air before your models even warm up.
Need a cohesive routing framework that keeps conversations fluid?
How to Measure End-to-End Voice AI Latency Accurately?
To instrument end-to-end latency accurately, you must inject unique trace IDs directly into the inbound Twilio SIP headers, recording timestamps at every internal state transition.
Production voice systems live and die on tail latency (the p95 and p99 metrics). If 5 out of every 100 callers experience a 3-second lag, your drop-off rates will spike.
We track the pipeline by isolating each transition point programmatically:
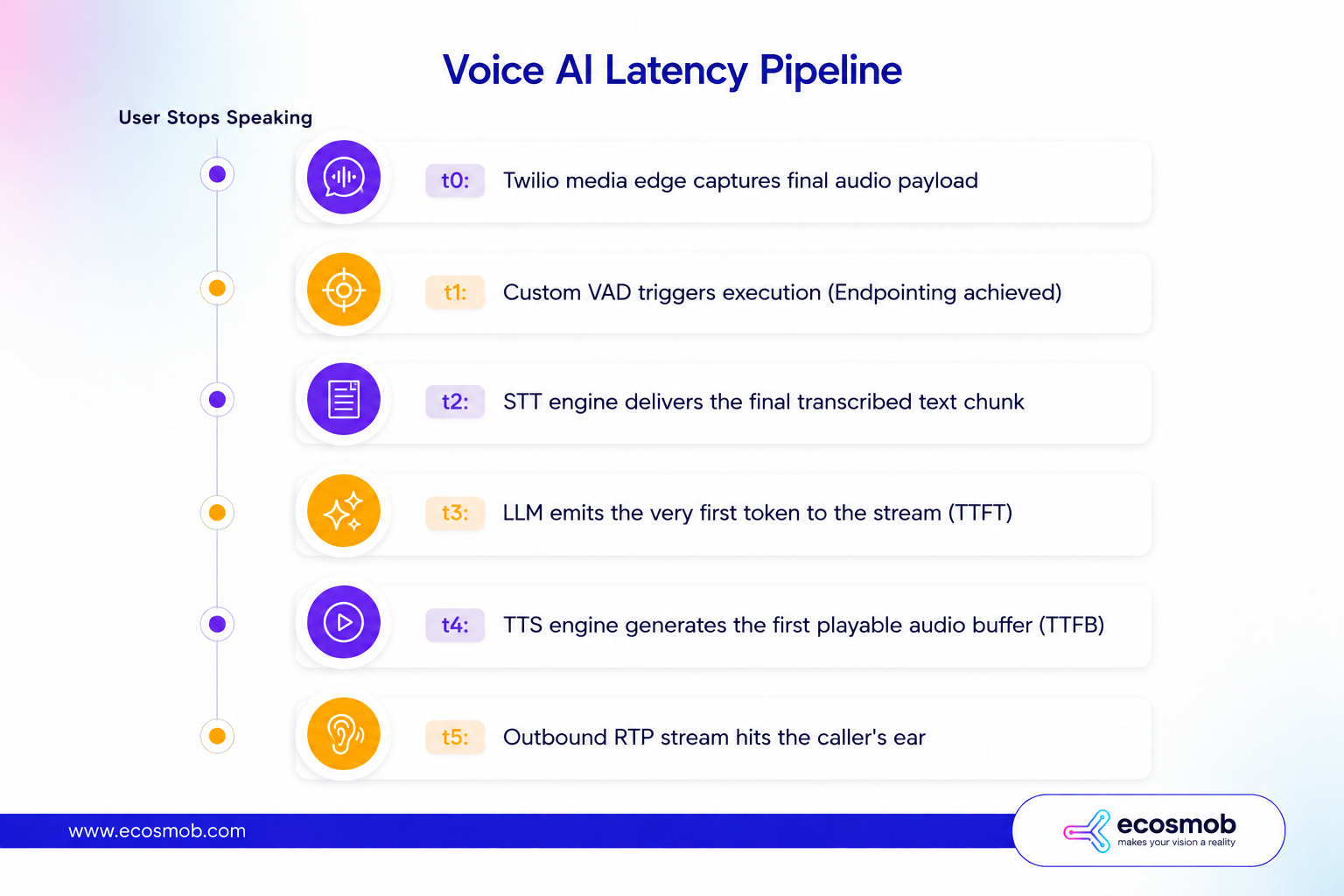 So, how do you isolate the real bottleneck?
So, how do you isolate the real bottleneck?
Subtract t2 from t3 to isolate your pure LLM processing time. Subtract t3 from t4 to find your actual audio synthesis time. If the gap between t0 and t1 is wider than 150ms, your VAD settings or endpointing models are what’s actively killing your customer experience.
Twilio Paths for Low Latency
When connecting an AI agent to Twilio, you have three primary architectural pathways to route the real-time audio. Each routing path fundamentally changes how your application ingests real-time audio data. So, choosing the right one establishes your baseline latency floor.
- Twilio Media Streams (WebSockets)
This approach opens a persistent, bidirectional WebSocket connection that streams raw audio (G.711 μ-law at 8kHz) directly to your server. It gives you raw access to the audio packets the moment they hit Twilio’s edge, allowing you to bypass external application logic entirely and run an optimized custom pipeline.
- Twilio ConversationRelay
A framework designed to handle the orchestration layer between the user and your backend by wrapping STT and TTS natively. While convenient for rapid prototyping and hitting a stable median speed, it introduces an abstraction layer that limits your ability to optimize raw audio packet handling for p99 tail latency.
- Direct SIP Routing
Direct SIP bypasses the programmable API layers entirely, terminating the carrier connection straight into your private media servers. This eliminates the edge-to-WebSocket conversion overhead entirely, offering the absolute lowest baseline infrastructure latency for high-volume enterprise architectures.
In short, you should use Twilio Media Streams via WebSockets or direct SIP routing for the lowest latency because they offer raw, unabstracted access to the media payload.
Hoping to stop losing customers to awkward 2-second phone pauses?
How to Ensure Sub-600ms Voice AI Latency Over Twilio SIP?
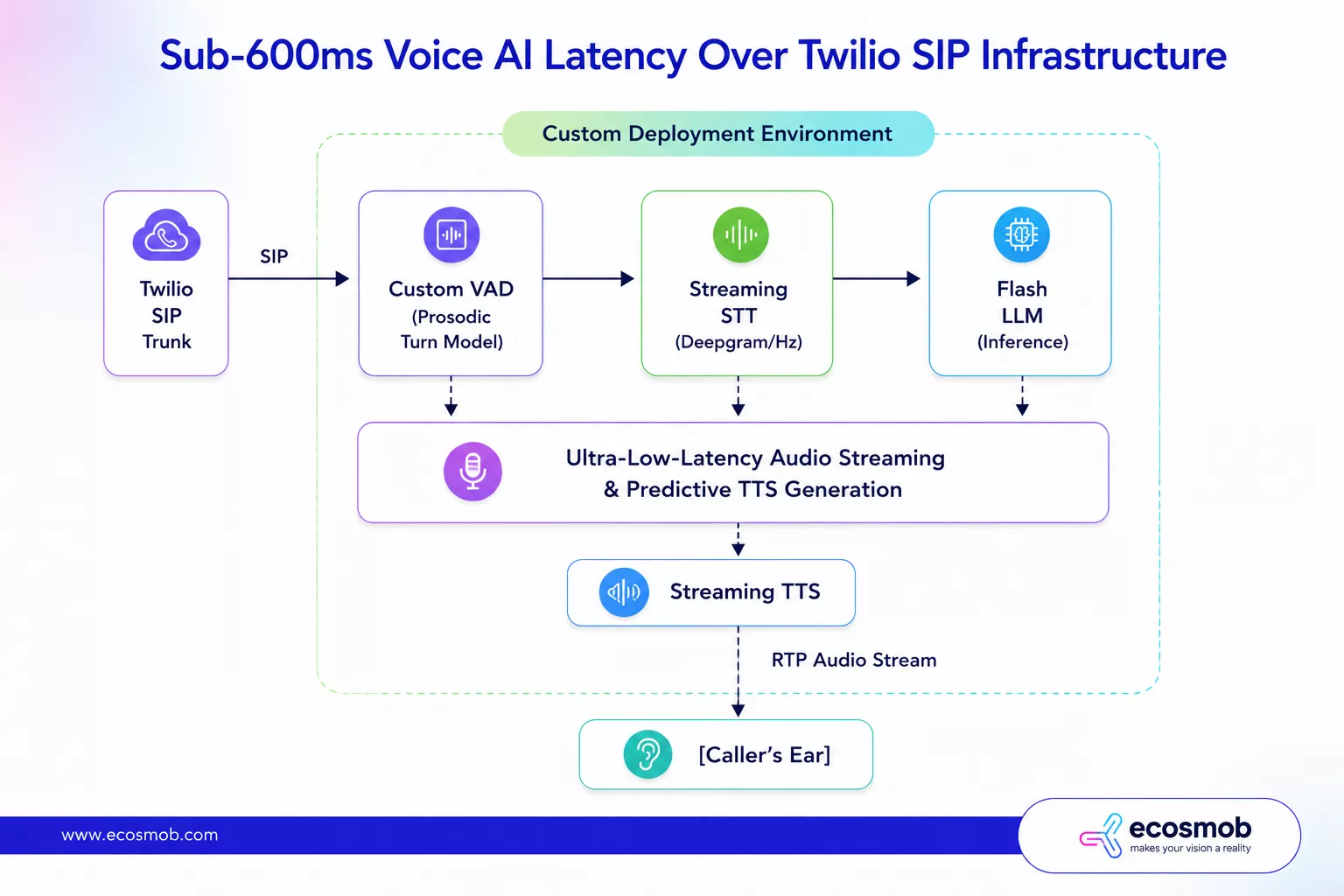
To hit sub-600ms over a reliable Twilio connection, you must throw away standard API wrappers and completely re-engineer the underlying infrastructure into a parallel, streaming framework.
 Overhaul Turn Detection
Overhaul Turn Detection
We replace simple silence-based VAD with a lightweight, contextual turn-prediction model. Instead of staring at a stopwatch waiting for dead air, the system analyzes cross-talk, pitch drops, and basic grammatical context clues. If a customer trails off naturally, the system flags an end-of-turn in just 80ms to 100ms, long before a standard silence timer would ever trigger.
Eliminate Cross-Cloud Network Hops
We co-locate our core orchestration engines, streaming STT modules, and local inference clusters inside highly optimized cloud nodes directly connected to the closest telephony exchange points. By removing unnecessary external cloud routing from the core loop, we reduce the multi-vendor transit tax to an absolute minimum.
Streaming and Parallel Token Synthesizing
We configure the LLM router to stream responses immediately. The exact millisecond the text engine generates the first few words of a sentence, those tokens are piped straight into a streaming Text-to-Speech (TTS) engine. The system begins converting those initial words into high-fidelity audio chunks while the rest of the paragraph is still being calculated by the language model.
Ecosmob Expert Tip
Don’t wait for your LLM or database to return a complex response for common, predictable human transitions. Build a quick-response cache layer that instantly streams soft vocal filler tokens (like “Let me look into that for you…” or “Sure, one second…”) using pre-rendered audio buffers while your main model processes a heavy query.
This drops your perceived latency to zero.
This drops your perceived latency to zero.
Building an AI voice solution that genuinely delights callers requires moving away from fragile, multi-vendor API chains and building a cohesive, custom-built architecture.
If you have outgrown rigid, off-the-shelf software and want to deploy high-scale, ultra-low-latency voice agents that you completely control, let’s build it the right way.
Talk to one of our AI-based voice experts today to design a high-performance communication platform tailored exactly to your architecture needs!
FAQs
What is the latency budget of a voice AI agent on Twilio SIP, broken down by stage?
The total budget must stay under 600ms for p95 tail performance. This requires allocating roughly 40-60ms for network ingress, 80-120ms for custom VAD, 100-150ms for streaming transcription, 180-240ms for LLM Time-to-First-Token, and 60-100ms for streaming audio synthesis.
Where does most of the latency actually come from in a typical Twilio voice AI deployment?
Most latency stems from multi-vendor cloud network hops across separate third-party APIs and naive Voice Activity Detection (VAD) configurations that enforce an artificial 500ms silence pause before initiating model processing.
What network and infrastructure changes have the biggest impact on tail latency (p95 and p99)?
Co-locating your custom routing engine, streaming modules, and localized inference clusters inside unified network nodes connected to primary carrier exchanges has the largest structural impact on eliminating tail latency spikes.
Why is tail latency (p95/p99) more important than median latency?
Tail latency determines the real-world customer experience for your busiest or most poorly routed calls. If your median speed is fast but your p95 is over 2 seconds, some of your users face completely broken conversations.
How does co-location improve voice AI performance?
Co-location reduces physical distance by hosting your transcription, LLM orchestration, and voice generation models inside the same private cloud infrastructure. This completely eliminates the multi-hop network delay caused by hopping across different cloud vendors.











