



































































QUICK SUMMARY
Traditional contact centers leak revenue through rigid dialogue trees and agent labor costs that scale linearly with call volume. Asterisk LLM voicebots break this model by handling unlimited concurrent conversations with human-level comprehension while learning from every interaction. This blog explains the technical integration architecture, concurrent capacity planning, cloud vs. on-premise deployment trade-offs, and continuous learning mechanisms that determine whether your AI-powered voicebots for Asterisk deliver measurable ROI or become abandoned technology experiments.
Contact centers face an economic paradox. Launch a successful campaign that doubles inbound call volume, and you must either disappoint customers with longer wait times or hire expensive new agents (but hire them only for peak periods and you’re overstaffed during normal hours). Traditional IVR systems handle this no better than agents. A customer calling with an issue that doesn’t fit the menu options experiences identical frustration whether they press buttons or wait for an agent.
AI-powered voicebots flip this through continuous comprehension of customer intent. And when call volume spikes, the voicebot absorbs the surge without hiring freezes, without per-agent licensing costs, without ramp-up time. When an agent does handle a call, they’re handling only calls that genuinely need human judgment, not routine requests that waste expensive labor.
That is Asterisk contact center automation, a fundamentally different model.
How Are LLM Voicebots Different from Traditional IVR?
Traditional IVR operates on finite state machines, which are predetermined dialogue trees where every possible conversation path must be manually programmed. When customers deviate from expected responses, the system fails with “I didn’t understand that, please try again.” Business logic changes require developers to rebuild entire flow diagrams.
Natural Language Comprehension vs. Keyword Matching
Legacy IVR systems use keyword detection (if audio transcription contains “billing,” route to billing). This breaks when customers say “I have a question about my recent charge” (no “billing” keyword). Asterisk AI systems powered by LLMs understand semantic meaning. They know “recent charge,” “what I was billed for,” and “the payment you took” all express billing intent, routing correctly without keyword presence.
Context Retention Across Conversation Turns
Traditional systems treat each interaction as isolated. Ask about an order, then ask “when will it arrive?”; the IVR has no idea what “it” refers to. LLM voicebots maintain conversation state automatically, understanding pronouns, implicit references, and multi-turn dialogue without requiring customers to repeat context every exchange.
However, research shows LLMs experience 30-40% accuracy degradation in extended multi-turn conversations due to context drift and lost-in-middle problems.
Production systems mitigate this through periodic context summarization, conversation re-framing, and strategic escalation to human agents when conversation complexity exceeds safe thresholds.
Adaptive Improvement Through Conversation Analysis
Rather than automatic retraining, successful Asterisk contact center automation systems analyze conversation patterns: which responses lead to escalations, which clarifications are requested repeatedly, and which intents are misidentified. These insights feed into prompt refinement and knowledge base updates (improvements that deploy within hours or days, not weeks of retraining).
Multi-Step Reasoning for Complex Scenarios
Simple IVR handles single-intent calls well: “check my balance” → retrieve balance → end call. Complex scenarios break the model. When customers say, “I need to change my shipping address for the order I placed yesterday, but keep billing the same,” traditional IVR can’t decompose this into discrete steps.
LLM voicebots parse complex multi-intent requests, execute ordered operations, confirm each step, and handle dependencies between actions (though escalation rates remain higher for these complex interactions compared to routine inquiries).
Legacy IVR is killing your conversion rates.
Architecture for Integrating LLM Engines with Asterisk
Production Asterisk LLM integration requires bridging Asterisk’s real-time media processing with AI inference pipelines that operate on fundamentally different timescales. The architecture must stream audio to AI services, process responses through STT/LLM/TTS pipelines, and return synthesized audio; all while maintaining sub-second latency that feels natural in conversation.
AudioSocket Protocol as the Integration Foundation
Asterisk’s AudioSocket module provides the architectural foundation for Asterisk AI integration by establishing direct TCP connections that stream raw audio bidirectionally. When calls arrive requiring AI handling, Asterisk’s dialplan routes them to AudioSocket, which connects to your AI integration server and streams 8kHz, 16-bit PCM audio in 320-byte chunks (20ms frames).
Your integration application receives this audio stream, processes it through Speech-to-Text engines (Deepgram, Google Cloud Speech, Whisper), sends transcriptions to LLM services (OpenAI GPT-4, Anthropic Claude, local models via Ollama), generates responses, synthesizes them through Text-to-Speech services (ElevenLabs, Google TTS, Coqui), and streams resulting audio back through the AudioSocket connection. Asterisk receives synthesized audio and plays it to callers without interruption.
This architecture maintains separation of concerns: Asterisk handles telephony complexities (SIP signaling, codec transcoding, call control), while external services handle cognitive processing. AI inference latency doesn’t block Asterisk’s media threads, preserving PBX stability even when AI services experience slowdowns.
STT/LLM/TTS Pipeline Architecture
The processing pipeline consists of three distinct stages, each optimizable independently:
Speech-to-Text (STT) for Real-Time Transcription
Audio chunks from AudioSocket feed continuously into streaming STT engines (you don’t wait for complete utterances before processing begins).
Voice Activity Detection (VAD) identifies natural pauses where users finish speaking, triggering LLM processing without requiring explicit silence periods.
LLM Inference for Conversational Intelligence
Transcribed text enters the LLM with conversation context (previous exchanges, customer data, business rules). The LLM generates contextually appropriate responses based on trained knowledge and real-time information. Streaming LLM APIs (OpenAI’s streaming endpoints, Anthropic’s streaming responses) return tokens as they’re generated rather than waiting for complete responses, reducing perceived latency by hundreds of milliseconds.
Text-to-Speech (TTS) for Natural Voice Synthesis
Generated text feeds into TTS engines that produce natural-sounding speech. Modern neural TTS (ElevenLabs, Google WaveNet) creates remarkably human-like prosody, emotional inflection, and naturalness that older concatenative systems couldn’t achieve. Streaming TTS APIs begin audio synthesis before the complete text arrives, further reducing end-to-end latency.
Tools and APIs That Connect Asterisk with LLM engines
| Component | Primary Technologies | Purpose | Key Advantage |
| Audio Streaming | Asterisk AudioSocket, Python/Go TCP servers | Bidirectional audio transport | Direct PCM streaming without codec overhead |
| Speech Recognition | Deepgram, Google Cloud Speech, Whisper API | Real-time transcription | Streaming partial results reduces latency |
| LLM Processing | OpenAI API, Anthropic Claude API, Ollama (local) | Conversational intelligence | Context retention across multi-turn dialogue |
| Voice Synthesis | ElevenLabs, Google TTS, Coqui, Azure Speech | Natural speech generation | Neural models create human-like speech |
| Orchestration | AVR (Agent Voice Response), custom Python/Node.js | Pipeline coordination | Manages state, handles failures, routes audio |
Will AI-Powered Asterisk Support Thousands of Concurrent Calls?
The honest answer: it depends entirely on your architecture. Asterisk itself handles thousands of concurrent calls reliably, but AI processing introduces new bottlenecks that poorly designed integrations turn into catastrophic failure points.
Asterisk’s Core Capacity Remains Unchanged
Asterisk’s media processing capacity shouldn’t degrade when integrating AI. If your server handled 2,000 concurrent calls before AI integration, it still handles 2,000 concurrent calls after, assuming AI processing happens externally.
The AudioSocket protocol streams audio over TCP without consuming significant Asterisk resources. Problems arise when AI integration applications run on the same server as Asterisk, competing for CPU, memory, and network bandwidth.
Realistic AI conversation capacity depends on LLM latency and architecture quality. Each LLM interaction (STT + inference + TTS) takes 700ms to 2+ seconds (sometimes even more). During this time, integration servers maintain state, buffer audio, and wait for responses. All of this affects the number of concurrent conversations your AI-powered voicebots for Asterisk can handle.
Architectural Patterns That Scale to Thousands of Concurrent AI Calls
Here’s what can help hit your target for concurrent calls:
Separate Infrastructure for AI Processing
Deploy Asterisk on dedicated servers optimized for media processing. Run AI integration applications on separate servers optimized for I/O-bound workloads. This isolation prevents AI processing spikes from stealing CPU cycles during Asterisk’s critical media frame processing windows.
Asynchronous, Non-Blocking I/O Throughout
Use programming languages and frameworks designed for concurrent I/O. Never block threads waiting for AI API responses; process audio streams asynchronously, queue requests, and handle responses via callbacks or event loops.
Connection Pooling to AI Services
Maintain persistent HTTP/2 or WebSocket connections to STT/LLM/TTS providers. Connection establishment overhead (TCP handshake, TLS negotiation) adds 50-200ms per request. Reusable connection pools eliminate this latency, while HTTP/2 multiplexing allows hundreds of concurrent requests over a single connection.
Horizontal Scaling with Load Balancing
Deploy multiple AI integration servers behind load balancers. Asterisk distributes AudioSocket connections across the server pool based on current load. As concurrent calls increase, add servers dynamically. This scales AI processing capacity independently of Asterisk’s media capacity.
Your customers expect intelligent support in 2026. Build it with Asterisk + LLM!
Cloud-Based vs. On-Premise LLM Models
The cloud-versus-local decision for Asterisk LLM deployments isn’t about cost alone. It’s about latency, data sovereignty, operational complexity, and model capability trade-offs that dramatically affect user experience.
Cloud-based LLM advantages
- Providers like OpenAI, Anthropic, and Google offer state-of-the-art models with capabilities that local deployments can’t match.
- Cloud APIs handle scaling automatically (your integration code doesn’t change whether handling 10 concurrent calls or 10,000).
- Updates and improvements deploy without your intervention; models get smarter over time with zero maintenance cost.
Cloud-based LLM disadvantages
- Every call sends audio data to external providers, creating data sovereignty concerns for regulated industries (healthcare, finance, government).
- Network latency adds 50-200ms per request, depending on geographic distance to API endpoints.
- API costs scale linearly with usage. At high call volumes, per-minute charges become substantial ongoing expenses.
- Service availability depends on providers, and outages affect your entire contact center instantly.
On-premise LLM advantages
- Complete data control. Audio never leaves your infrastructure, satisfying strict compliance requirements.
- Zero per-call API costs after initial hardware investment.
- Predictable latency independent of internet connectivity.
- Customization freedom (fine-tune models on your specific domain data, terminology, and business logic without sharing training data externally).
On-premise LLM disadvantages
- Hardware requirements are substantial. GPU servers capable of running capable models cost tens of thousands initially.
- Model capabilities lag behind cloud providers; local models struggle with complex reasoning that GPT-4 handles easily.
- Operational burden includes model deployment, monitoring, updating, and troubleshooting.
- Scaling requires purchasing additional hardware with long procurement lead times.
For balance, you can go with hybrid architectures.
- Run commodity interactions (account lookups, appointment scheduling, FAQ responses) on local models where latency and cost matter most.
- Route complex reasoning tasks (troubleshooting, negotiation, nuanced support) to cloud APIs where model capability justifies the cost.
This hybrid approach optimizes both cost and capability while maintaining acceptable performance.
Ecosmob Expert Tip
Start with cloud-based AI for initial deployment to validate use cases and refine prompts without infrastructure investment. Once call volumes justify it, and you’ve identified high-frequency interaction patterns, migrate those specific flows to on-premise models while keeping cloud AI for edge cases.
This phased approach minimizes risk while building toward cost-optimized architecture.
How to Ensure Call Stability During AI Interactions?
AI services fail. APIs timeout, rate limits trigger, models return errors, and network connections drop. In poorly designed Asterisk contact center automation, these failures disconnect calls. Production architectures require failover mechanisms where AI failure becomes invisible to callers.
Pre-Call Health Checks Prevent Routing to Dead Services
- Before routing calls to AI processing, verify service health through lightweight API checks.
- Maintain shared state (Redis, Memcached) tracking AI service availability, updated continuously by background health monitoring.
- If AI services are unhealthy, route calls directly to human agents or fallback to IVR instead of attempting AI processing that will fail.
Timeout-based Failover Triggers
- Set aggressive timeouts for AI responses (typically 5 seconds total per interaction). If STT transcription, LLM inference, or TTS synthesis exceeds thresholds, trigger fallback immediately.
- Play pre-recorded messages (“Let me connect you with a specialist”) and transfer to human agents. Calls stay connected; callers experience brief pauses followed by human pickup rather than dead silence and disconnection.
Graceful Degradation to Simpler AI or IVR
- Maintain fallback tiers: if advanced GPT-5 integration fails, fall back to simpler local LLM handling basic queries.
- If all LLM services fail, fall back to traditional IVR with DTMF navigation.
Each tier provides progressively simpler intelligence while maintaining call connectivity throughout.
State Preservation Across Failover
Before transferring from AI to human agents, capture conversation context (customer account, intent identified, information collected) and pass it via Asterisk channel variables. Agents receive screen-pops with full context, eliminating redundant questions. From the customer’s perspective, the conversation continues seamlessly despite backend failover.
How to Update Voicebots as Customer Needs Evolve?
Static Asterisk AI deployments become obsolete rapidly as products change, policies update, and customer language patterns evolve. Production systems require continuous improvement mechanisms that enhance voicebot intelligence without manual developer intervention for every change.
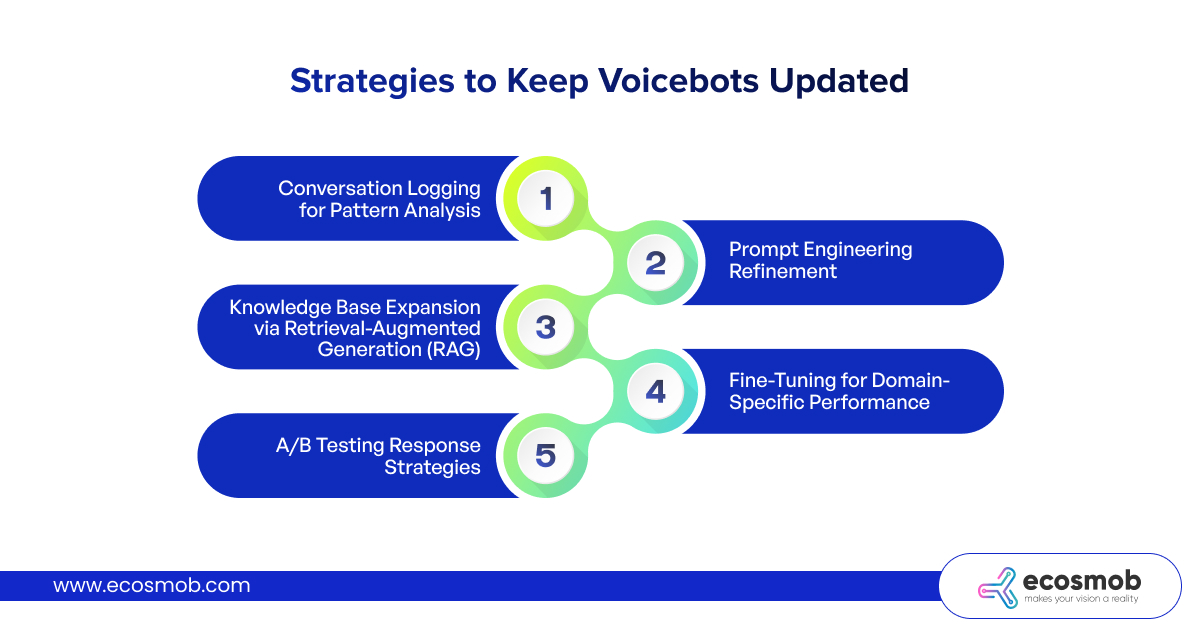 Conversation Logging for Pattern Analysis
Conversation Logging for Pattern Analysis
- Store complete transcripts of AI interactions: user utterances, LLM responses, resolution outcomes, customer satisfaction signals.
- Analyze failed interactions where customers requested human escalation, where resolution took excessive turns, or where satisfaction scores were low. These failures reveal gaps in current training.
Prompt Engineering Refinement
LLM behavior depends heavily on system prompts (instructions that define role, constraints, and response patterns).
Continuously refine prompts based on performance data: when many customers misunderstand a specific response pattern, rephrase prompts to generate clearer explanations. When the bot fails to recognize certain intent phrasings, add examples (few-shot learning prompts).
Knowledge Base Expansion via Retrieval-Augmented Generation (RAG)
Create a knowledge base (vector database) of past successful conversations plus FAQ updates, policies, and product information. When LLMs generate responses, they retrieve similar past interactions and adapt context accordingly.
When you update return policies, add them to the RAG database; AI immediately references current information without manual retraining.
Fine-Tuning for Domain-Specific Performance
Generic LLMs don’t understand your industry terminology, product names, or business-specific processes. Fine-tune models on your conversation corpus to improve domain accuracy.
A/B Testing Response Strategies
Deploy multiple prompt variations or model configurations simultaneously, routing subsets of calls to each variant.
- Measure resolution rates, customer satisfaction, and average handling time across variants.
- Automatically promote winning strategies to full deployment while retiring underperforming approaches (continuous optimization without guesswork!).
SIP Server Integration and Ecosmob’s Voicebot Connector
Beyond Asterisk, complete contact center architectures often involve SIP servers (Kamailio, OpenSIPS) for load balancing, session management, and routing intelligence. Asterisk AI deployments at scale require these components to work cohesively.
Ecosmob’s Voicebot Connector simplifies the integration complexity by providing a tested bridge between SIP infrastructure, Asterisk, and AI engines. The connector handles protocol translation, manages state synchronization, and ensures that AI processing integrates seamlessly with your existing telephony stack without requiring deep VoIP protocol expertise from your AI team.
For organizations exploring alternatives, similar integration patterns apply to FreeSWITCH LLM voicebots: the architectural principles of AudioSocket-equivalent protocols, asynchronous processing, and failover design remain consistent across modern open-source PBX platforms.
The contact center transformation is very much here and is highlighting the companies that are thinking ahead. Organizations deploying intelligent Asterisk AI systems report a reduction in agent-handled call volume, faster resolution times for routine interactions, and measurable improvements in customer satisfaction when routing decisions match conversation complexity.
But the technology only delivers these results when implemented correctly.
Poor architecture creates systems that work impressively in demos with a few concurrent calls and collapse under a production load of thousands.
We’re beyond the choice of whether to implement AI-powered voicebots for Asterisk.
You should be building production-grade hybrid architectures (AI + strategic human escalation) that scale reliably and improve customer outcomes, or experimental systems that get quietly abandoned after failing to deliver promised ROI.
Ready to build contact center intelligence that actually works at scale?
Work with experts who’ve deployed these systems in production!
FAQs
How do I integrate LLM voicebots with my existing Asterisk system?
Use Asterisk's AudioSocket module to stream audio via TCP to integration servers running STT/LLM/TTS pipelines. Deploy orchestration layers (Python with asyncio, Node.js) that coordinate between Asterisk audio streams and AI service APIs without blocking Asterisk's media processing.
Will Asterisk support thousands of AI-powered interactions simultaneously?
Yes, if architected correctly. Deploy Asterisk and AI processing on separate infrastructure, use asynchronous non-blocking I/O patterns, implement connection pooling to AI services, and horizontally scale AI integration servers behind load balancers as concurrent call volume grows.
What tools connect Asterisk with LLM engines?
AudioSocket protocol for audio streaming, Python/Go TCP servers for integration logic, Deepgram/Google/Whisper for STT, OpenAI/Anthropic/Ollama for LLM processing, ElevenLabs/Google/Coqui for TTS, and orchestration platforms like AVR (Agent Voice Response) managing the complete pipeline. (Ecosmob's Voicebot Connector simplifies integration with existing SIP infrastructure.)
Can LLM bots route calls more intelligently than traditional systems?
Semantic understanding outperforms keyword matching significantly. LLMs achieve higher intent classification accuracy in production settings, understand phrasing variations, and route correctly even when customers don't use expected terminology. However, routing intelligence should be paired with escalation logic for complex conversations rather than treating routing accuracy as sufficient for full automation.
Should I use cloud-based or on-premise LLM models?
Cloud AI offers state-of-the-art capabilities, automatic scaling, and zero maintenance, but introduces data sovereignty concerns and per-call costs. On-premise models provide data control and zero per-call costs but require substantial hardware investment and operational expertise. Hybrid approaches optimize both cost and capability, running routine interactions on local models while routing complex reasoning to cloud APIs.











