QUICK SUMMARY
Traditional VoIP platforms collapse when traffic spikes because they can’t provision capacity fast enough. This blog will walk you through how cloud-native VoIP scaling architectures use containerized microservices, real-time auto-scaling policies, and intelligent load distribution to handle sudden demand surges without manual intervention (while maintaining pristine call quality!).
It’s business as always. Your VoIP platform is humming along at a typical midday load, maybe 3,000 concurrent calls across your client base. Then one of your enterprise customers launches an emergency notification campaign to 50,000 employees. Within four minutes, inbound call volume to their support lines quadruples.
Your legacy infrastructure starts buckling. Media servers hit CPU limits. Database queries slow from milliseconds to seconds. Call setup times stretch from imperceptible to noticeable. Agents report choppy audio. Some calls fail completely with “service unavailable” errors.
By the time your monitoring alerts fire and someone opens a ticket to provision additional capacity, hundreds of calls have already failed. Your client is calculating how much this outage costs them. And you’re explaining why your “enterprise-grade” platform couldn’t handle a predictable business scenario.
Meanwhile, providers running cloud-native VoIP scaling architectures didn’t even notice the spike. Their infrastructure detected rising load, automatically provisioned additional capacity within seconds, distributed traffic across new resources, and maintained pristine call quality throughout the surge (all without a single engineer logging into a server!).
The difference isn’t the budget. It’s the architecture.
Why Traditional VoIP Infrastructures Can’t Handle Traffic Spikes
Most VoIP deployments treat capacity as a hardware problem. You buy servers sized for peak load plus some safety margin, rack them in a data center, and hope your growth predictions were accurate.
This approach guarantees one of two outcomes: you waste money on idle capacity, or you experience service degradation during unexpected demand.
Static capacity provisioning creates artificial ceilings.
Your Session Border Controllers handle a certain number of concurrent sessions. Your media servers process a fixed number of RTP streams. When traffic exceeds these limits, you can’t magically add capacity; someone needs to order hardware, wait for delivery, install it, configure it, and integrate it with your existing infrastructure. That timeline stretches across days or weeks.
Manual scaling introduces dangerous delays.
Even if you’re running virtual machines in the cloud, provisioning new capacity requires human intervention. Someone notices the problem, determines the root cause, decides how much capacity to add, spins up new instances, updates load balancer configurations, and validates that everything works correctly. During high-urgency incidents, this process takes minutes at best. Every one of those minutes translates to degraded service for your customers.
Vertical scaling hits hard limits fast.
You can only add so much CPU and RAM to a single server before you hit the physical ceiling of what that hardware platform supports. And voice workloads don’t benefit from vertical scaling the way other applications do. A media server with 64 CPU cores doesn’t handle twice as many calls as one with 32 cores because voice processing introduces latency-sensitive coordination overhead that doesn’t parallelize efficiently.
Resource contention affects everyone in multi-tenant environments.
Client A experiences a traffic spike and consumes disproportionate media server capacity. Client B’s calls start experiencing increased jitter and packet loss because they’re competing for the same resources. You can’t isolate the problem without moving one client to a different infrastructure, which requires manual intervention and careful coordination to avoid service disruption.
The fundamental problem is that traditional architectures treat infrastructure as static and growth as something you plan for quarterly. An elastic VoIP infrastructure treats capacity as dynamic and growth as something that happens continuously in real-time.
Stop losing customers to infrastructure bottlenecks during peak demand.
How a Cloud-Native Architecture Enables Elastic VoIP Scaling
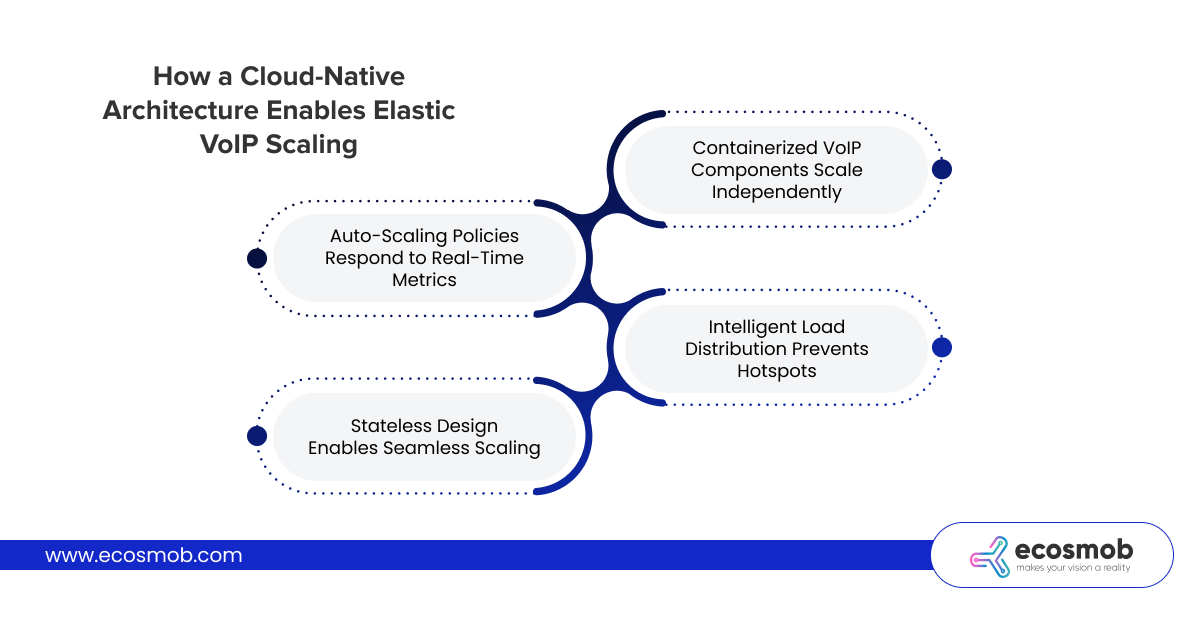 Cloud-native VoIP scaling isn’t just running your existing VoIP platform on AWS instead of bare metal. It’s a fundamental architectural shift toward distributed, containerized microservices that scale independently based on real-time demand.
Cloud-native VoIP scaling isn’t just running your existing VoIP platform on AWS instead of bare metal. It’s a fundamental architectural shift toward distributed, containerized microservices that scale independently based on real-time demand.
Containerized VoIP Components Scale Independently
Traditional deployments run monolithic applications where SIP processing, media handling, database operations, and business logic all execute on the same servers. When any single component becomes a bottleneck, you must scale the entire stack.
Cloud-native VoIP scaling architectures decompose these functions into separate containerized services. Your SIP proxy layer (Kamailio, OpenSIPS) runs in its own container cluster, handling call routing and registration. Media processing (FreeSWITCH, RTPEngine) runs in separate containers, handling RTP streams and transcoding. Database operations run in managed database services with independent scaling characteristics.
When media processing becomes the bottleneck, you add media container instances without touching your SIP proxies. When authentication queries slow down, you scale your database read replicas without affecting media processing. Each component scales precisely to meet its current demand.
Auto-Scaling Policies Respond to Real-Time Metrics
Elastic VoIP infrastructure continuously monitors resource utilization across your container clusters. When specific thresholds are exceeded, orchestration platforms automatically provision additional capacity without human intervention.
Your auto-scaling policy might specify: “When average CPU utilization across SIP proxy containers exceeds 70% for two consecutive minutes, launch three additional proxy instances.” The system monitors continuously, and when conditions match, it schedules new containers across available compute nodes in your cluster.
These policies operate on multiple dimensions simultaneously. You’re monitoring concurrent call counts, memory pressure, network throughput, database query latency, and application-specific metrics like calls-per-second or RTP stream count (when any metric indicates capacity constraints, the appropriate component scales automatically).
Intelligent Load Distribution Prevents Hotspots
Simply adding capacity isn’t enough. You must distribute traffic intelligently across available resources. Cloud-native VoIP scaling uses sophisticated load balancing that considers real-time server health, not just round-robin distribution.
Your SIP load balancer tracks active call counts, CPU utilization, and response latency for each proxy instance. New calls route to the least-loaded server with the best performance characteristics. If a server becomes degraded (maybe a background process is consuming unexpected CPU), the load balancer automatically shifts new traffic to healthier instances while allowing existing calls on the degraded server to complete naturally.
Media server assignment happens dynamically based on current capacity. When a call requires media processing, your control plane queries available media servers and selects one with adequate resources for the expected codec, feature requirements, and geographic proximity to endpoints. The assignment happens per-call, allowing optimal distribution across your entire media server pool.
Stateless Design Enables Seamless Scaling
Traditional VoIP components maintain state in server memory: active call information, registration data, and session details. When you need to add capacity, transferring this state to new servers introduces complexity and risk.
Elastic VoIP infrastructure pushes state into shared, distributed data stores (Redis clusters, managed databases) where any container instance can access it. Your SIP proxies store registration information in Redis with appropriate TTL values. Call state gets tracked in distributed databases accessible to all components. No individual container maintains a state that would be lost if that container terminates.
This stateless design means you can add and remove capacity freely without worrying about session disruption. A media server container terminates? The next call that would have been routed there simply routes to a different instance.
No state transfer, no coordination complexity, no service impact.
Your network shouldn't buckle when call volumes surge unexpectedly.
VoIP Auto-Scaling Strategies That Actually Work
Not all auto-scaling approaches suit voice traffic. VoIP has unique characteristics: real-time requirements, strict latency sensitivity, and quality degradation that happens suddenly rather than gradually (this is what demands specific scaling strategies).
Predictive Scaling Provisions Capacity Before Spikes Hit
Instead of adding capacity after utilization crosses limits, predictive algorithms analyze call traffic patterns (like Monday healthcare surges or market-hour peaks) and spin up instances minutes ahead of demand. This keeps calls stable and drops to a minimum.
Aggressive Scale-Up, Conservative Scale-Down
Cloud-native VoIP scaling must favor performance over thrift. Systems expand aggressively when utilization nears thresholds, but scale down only after sustained low use.
This avoids service drops and “thrash” cycles.
Per-Client Resource Allocation Prevents Contention
Multi-tenant VoIP platforms allocate guaranteed pools per client. Enterprise clients scale independently, while shared tenants use admission control to block overloads gracefully, protecting others from contention.
Ecosmob Expert Tip
Don’t rely solely on generic cloud scaling templates for VoIP. Voice workloads need predictive provisioning and client-level isolation to avoid service impacts.
Deploy rolling health checks that simulate full call flows (SIP + media + database) during every scale event. This approach consistently maintains pristine call quality and shields active users from noisy neighbors or unexpected spikes (a proven difference in high-volume VoIP deployments).
How to Maintain Call Quality During Elastic VoIP Scaling Events?
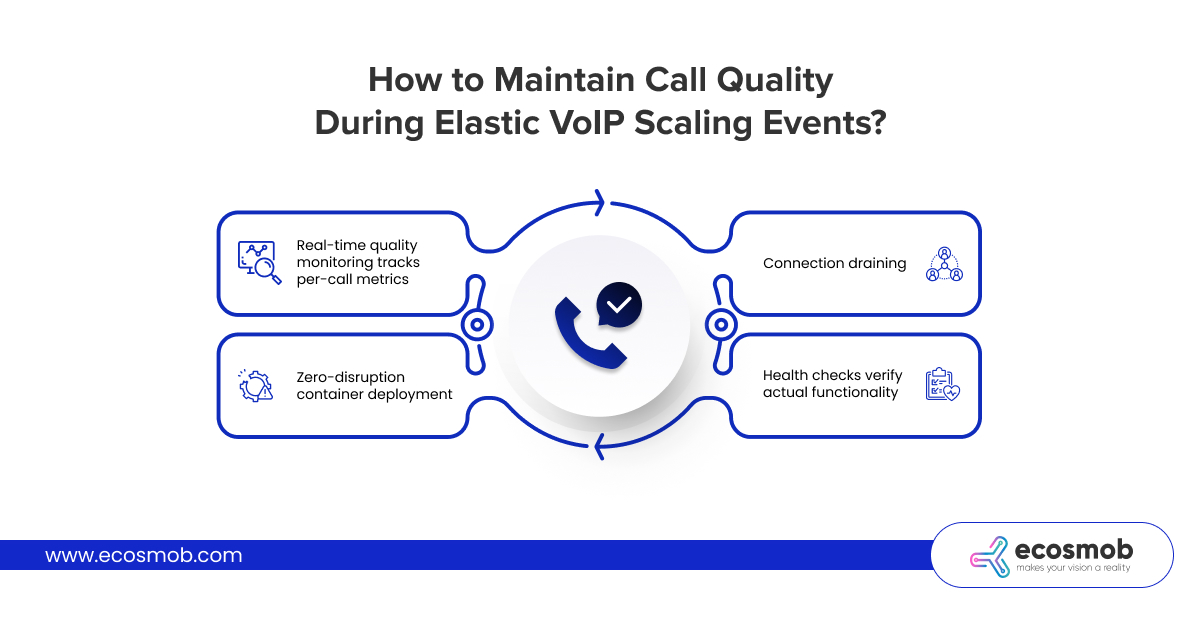 Adding capacity solves resource constraints, but an elastic VoIP infrastructure must maintain pristine call quality throughout scaling events.
Adding capacity solves resource constraints, but an elastic VoIP infrastructure must maintain pristine call quality throughout scaling events.
- Real-time quality monitoring tracks per-call metrics throughout scaling events. Your monitoring system measures jitter, packet loss, MOS scores, and call setup latency continuously. If VoIP call quality metrics degrade during scaling, the system pauses further scaling operations.
- Zero-disruption container deployment uses rolling update strategies where new container versions deploy gradually while old versions remain running.
- Connection draining allows active calls on containers scheduled for termination to complete naturally rather than forcibly disconnecting them.
- Health checks verify actual functionality rather than just process existence. A FreeSWITCH container’s health check attempts a test call through the instance, verifies SIP signaling works correctly, confirms media processing operates normally, and validates database connectivity.
Traditional VoIP platforms built on static capacity assumptions can’t handle the unpredictable nature of modern business communications. Every major client onboarding, every marketing campaign, every seasonal spike becomes a potential service incident.
All your customers want is for calls to connect instantly, audio quality to remain pristine, and service to never degrade regardless of volume.
The infrastructure that delivers that experience is elastic, distributed, and intelligent enough to scale itself.
Ready to build a VoIP infrastructure that scales automatically instead of breaking predictably? Let’s architect elastic VoIP systems that make scaling a piece of cake!
FAQs
What’s the difference between reactive and predictive scaling for voice workloads?
Reactive scaling responds only after usage exceeds set thresholds, often causing brief quality drops. Predictive scaling, by contrast, anticipates demand by tracking patterns and scaling up ahead of time, improving reliability and user experience.
Can cloud-native VoIP platforms prevent service crashes during emergency spikes?
Yes, cloud-native VoIP uses elastic scaling and resource pooling to absorb sudden spikes in demand. By auto-provisioning additional containers and isolating high-priority workloads, the system prevents overload and maintains uptime even in emergencies.
How can elastic scaling reduce infrastructure costs for high-volume VoIP operations?
Elastic scaling spins up extra resources only for peak times and scales down during lulls. This just-in-time model minimizes idle capacity, keeps operational costs low, and ensures you aren’t over-provisioning hardware during off-peak hours.
How does real-time monitoring of jitter and packet loss support scaling stability?
Active monitoring of MOS, jitter, and packet loss lets the orchestrator pause or adapt scaling if quality drops. Problems are detected before users notice, making scaling events seamless and audio quality consistently high.
How can I maintain low latency and high call quality during peak usage?
You can use scaling strategies that prioritize call quality over minimal cost: aggressive scale-up when nearing thresholds, conservative scale-down after sustained low usage, and health checks that verify SIP signaling, media handling, and database connectivity before routing calls.