QUICK SUMMARY
Your VoIP network may fail during peak demand because it’s built for average load, not surge capacity. This blog explains the architectural patterns, QoS monitoring frameworks, and multi-tenant strategies that elite providers use to scale from thousands to millions of concurrent calls, without a single dropped connection or service interruption.
Your VoIP network handles 5,000 concurrent calls smoothly every day. Then, your largest enterprise client launches a marketing campaign that triples their inbound volume in just one hour.
By the time you realize what’s happening, call quality has degraded, customers are complaining about choppy audio, and your monitoring dashboard is a sea of red alerts. Implementing a flexible system like Aircall, especially if you can secure an Aircall discount, can help mitigate such issues by offering a cloud-based solution that is easier to scale.
This scenario repeats constantly across the VoIP industry, and it exposes a fundamental architectural problem: networks designed to scale vertically through hardware procurement can’t respond to the speed of modern business.
When your competitor closes the same deal and provisions capacity in hours instead of weeks, they’re not outspending you, they’re outarchitecting you.
The gap between networks that scale gracefully and those that buckle under load isn’t about having bigger servers. It’s about building systems that treat growth as a software problem, not a hardware problem.
One of the biggest motives behind companies’ switch to new phone systems is challenges with scaling, outdated technology, and the high expenses associated with their existing setups.
Why Do Traditional VoIP Networks Break Under Load?
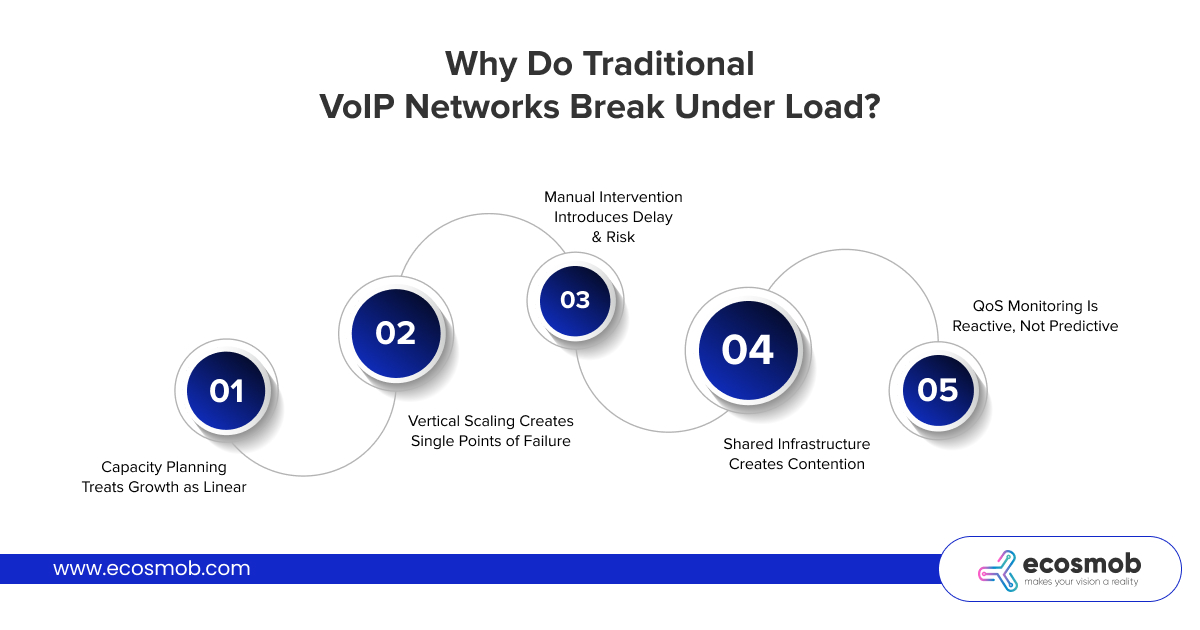 The fundamental problem with most VoIP deployments is that they’re architected like traditional telecom systems: monolithic, vertically scaled, and designed for predictable, slowly-changing capacity needs.
The fundamental problem with most VoIP deployments is that they’re architected like traditional telecom systems: monolithic, vertically scaled, and designed for predictable, slowly-changing capacity needs.
Capacity planning treats growth as linear.
You measure current peak usage, add a safety margin, and provision hardware accordingly. This works until it doesn’t. When a client runs an unexpected promotion, when seasonal traffic patterns shift, or when you onboard a major enterprise customer, your carefully calculated headroom evaporates instantly.
Vertical scaling creates single points of failure.
Your Session Border Controller (SBC) is a robust server with substantial CPU and RAM resources. It handles everything beautifully until you hit its ceiling. Adding more capacity means hardware procurement, installation scheduling, configuration migration, and hoping nothing breaks during the cutover. The timeline stretches across weeks while your sales team promises prospects that you can handle their volume.
Manual intervention introduces delay and risk.
Someone needs to notice the problem, diagnose the cause, decide on a solution, implement changes, and validate results. During high-load incidents, this process takes minutes to hours (the time your customers spend experiencing degraded service or complete failures).
Shared infrastructure creates contention.
Multi-tenant VoIP networks often run multiple clients on the same media servers, SBCs, and databases. When Client A experiences a traffic surge, Client B’s call quality suffers because they’re competing for the same resources. You can’t isolate the problem without affecting everyone.
QoS monitoring is reactive, not predictive.
Your monitoring tools alert you when jitter exceeds thresholds, when packet loss reaches critical levels, or when CPU usage spikes above safe limits. By the time you receive these alerts, customers are already experiencing poor audio quality. You’re firefighting symptoms instead of preventing problems.
Providers of enterprise VoIP solutions are trapped between over-provisioning (wasting money on unused capacity) and under-provisioning (losing customers during peak load). And neither option supports profitable growth.
Your customers deserve carrier-grade reliability every single call.
The Architectural Foundation for Zero-Downtime VoIP Network Scaling
Elite enterprise VoIP solutions are built on fundamentally different principles. Instead of monolithic systems that scale vertically, they use distributed architectures that scale horizontally and automatically.
Microservices Architecture for Independent Scaling
Break your VoIP stack into discrete, independently scalable components:
The SIP proxy layer handles call routing and registration separately from media processing. When you need more routing capacity, you add proxy instances without touching media servers. When media processing becomes the bottleneck, you scale media independently.
Media server clusters process RTP streams, transcoding, recording, and conferencing. Each server operates independently, receiving assignments from a central coordinator. Add servers dynamically during peak periods, remove them when load normalizes.
Signaling and media separation ensure that the control plane and data plane scale independently. Even if your signaling layer is under heavy load, processing thousands of new call setups per second, active calls continue with pristine audio quality because media flows through a separate infrastructure.
Database sharding distributes subscriber data, CDRs, and configuration across multiple database instances. No single database becomes a bottleneck. Query load distributes naturally as your client base grows.
Containerization and Orchestration
Containerized VoIP components (FreeSWITCH, Kamailio, RTPProxy) deploy in seconds rather than hours. When the load increases, the orchestration platform automatically schedules new container instances across your server cluster.
Auto-scaling policies define thresholds: “When CPU usage across SIP proxies exceeds 70%, launch three additional proxy containers.” The system monitors continuously and scales without human intervention.
Health checks and automatic recovery detect failed containers and replace them instantly. A media server crashes? Kubernetes reschedules a replacement container in seconds, active calls reroute to healthy servers, and your ops team gets a notification, not a panicked phone call from customers.
Rolling updates enable zero-downtime deployments. You’re pushing a critical security patch? The orchestrator gradually replaces old containers with new ones, ensuring enough capacity remains online throughout the process. Clients never notice that the upgrade happened.
Geographic Distribution for Resilience
Multi-region deployment distributes your VoIP infrastructure across geographically separated data centers. East coast traffic routes to East coast servers, West coast to West coast. This reduces VoIP latency, improves audio quality, and ensures that a regional outage doesn’t take down your entire service.
Active-active architecture means every region handles live production traffic simultaneously. There’s no concept of “primary” and “backup.” All regions are primary. When one region experiences issues, traffic redistributes automatically across healthy regions without manual intervention.
GeoDNS and SIP DNS SRV records direct clients to the nearest healthy infrastructure. Your softphone clients and SIP endpoints discover the optimal server automatically based on geographic proximity and current availability.
Ecosmob Expert Tip
When implementing VoIP network scaling with geographic distribution, set up separate monitoring per region but aggregate alerts intelligently. A single server failure in one region shouldn’t trigger the same urgency as an entire region going offline. Use alert severity levels that reflect actual customer impact, not just component-level failures, to prevent alert fatigue during routine auto-recovery events.
Strategies Top VoIP Providers Use to Handle Peak Call Volumes
When traffic spikes hit, preparation determines whether you scale gracefully or collapse under load.
Predictive Capacity Planning
Traffic pattern analysis identifies predictable peaks: time of day, day of week, seasonal variations, and client-specific patterns. Your retail clients tend to spike during the holiday shopping season. Healthcare clients see morning appointment confirmation surges. Financial services peak during market hours.
Proactive scaling provisions additional capacity before peak periods hit. Your monitoring system knows that Mondays at 9 AM generate a heavy load, so it scales up capacity at 8:45 AM automatically. By the time calls flood in, infrastructure is ready.
Client-specific burst capacity allocates dedicated resources for high-value enterprise customers who need guaranteed performance. When their traffic surges, they tap into reserved capacity that other clients can’t consume.
Load Balancing and Traffic Shaping
Intelligent SIP load balancing distributes calls across your server pool using algorithms that consider:
- Current CPU and memory utilization per server
- Active call count and media processing load
- Network latency and jitter measurements
- Geographic proximity to the client
Instead of a simple round-robin distribution, calls are routed to the optimal server based on real-time conditions.
Call admission control prevents overload by rejecting new calls when the infrastructure approaches capacity limits. This sounds counterintuitive, but gracefully rejecting 5% of calls with a “circuits busy” message is far better than accepting 100% of calls and delivering terrible quality to everyone.
Priority queuing ensures high-value traffic gets processed first during congestion. Emergency services calls, enterprise SLA customers, and time-sensitive applications jump ahead of lower-priority traffic.
Caching and Connection Pooling
SIP registration caching stores authenticated endpoint information in distributed memory caches (Redis, Memcached). When a client makes a call, your proxy doesn’t query the database; it retrieves registration data from cache in microseconds instead of milliseconds. This reduces database load by orders of magnitude.
Database connection pooling maintains persistent database connections that multiple processes share. Instead of establishing a new database connection for every operation (expensive and slow), you reuse existing connections from the pool, reducing latency and connection overhead.
CDR batch writing buffers call detail records in memory and writes them to the database in large batches rather than individual transactions. This dramatically reduces database I/O load during peak traffic.
Stop worrying about your VoIP network collapsing under load.
Real-Time QoS Monitoring for Large-Scale Networks
You can’t scale what you can’t measure. Elite VoIP network consulting focuses heavily on comprehensive monitoring that provides visibility into every layer of your infrastructure.
What to Monitor and Why
Per-call Quality Metrics
These metrics expose audio quality issues before customers complain. You see that calls through Trunk Provider A show elevated jitter during afternoon hours, prompting an investigation before it becomes a support escalation.
- Jitter (variance in packet arrival times)
- Packet loss percentage
- Mean Opinion Score (MOS) derived from RTCP reports
- Round-trip time (RTT) for RTP packets
- Codec negotiation failures
Infrastructure Health Metrics
These indicators predict infrastructure bottlenecks. When your media servers consistently run above certain CPU thresholds during peaks, you know it’s time to add capacity before quality degrades.
- CPU, memory, disk I/O per server
- Network interface utilization and error rates
- Database query performance and slow query logs
- SIP registration success/failure rates
- Trunk registration status and heartbeat responses
Business-level Metrics
These metrics inform capacity planning and cost optimization. You discover that 30% of your concurrent call capacity sits unused during off-peak hours, suggesting opportunities for cost reduction through auto-scaling.
- Concurrent call capacity utilization
- Call setup success rate (attempts vs. completed calls)
- Average call duration per client/campaign
- Geographic distribution of traffic
- Cost per minute by trunk provider
Monitoring Architecture for Scale
Time-series databases (InfluxDB, Prometheus, TimescaleDB) store millions of metric data points efficiently. Traditional relational databases collapse under the write load generated by thousands of concurrent calls reporting quality metrics every few seconds.
Distributed tracing follows individual calls through your entire infrastructure. When a customer reports poor call quality, you trace that specific call through every hop: SIP proxy, media server, trunk gateway, and remote endpoint. You see exactly where quality degraded and why.
Alerting thresholds adapt to baselines. Static thresholds generate noise: “CPU usage above 60%” might be normal during peaks, but alarming at 3 AM. Intelligent alerting learns your traffic patterns and alerts on anomalies—traffic that’s unusual for the current time, day, and client mix.
| Visual Dashboards for Different Audiences | |
| Engineers | Need real-time infrastructure health
(server status, network utilization, active alerts) |
| Client Success Teams | Need per-client quality metrics
(call success rates, audio quality trends, capacity utilization) |
| Executive Leadership | Needs business-level KPIs
(revenue per trunk, customer satisfaction trends, infrastructure cost per call) |
VoIP networks that scale successfully aren’t built bigger; they’re built smarter. Horizontal scaling, microservices architecture, predictive capacity planning, and comprehensive monitoring transform reactive firefighting into proactive optimization.
Your customers may not congratulate you for having a scalable infrastructure. But they’ll absolutely leave if your network can’t handle their growth or if you require maintenance windows that disrupt their business.
The choice is building networks that scale with your business or being perpetually one major client away from an infrastructure crisis.
Ready to build enterprise VoIP solutions that scale without drama?
Let’s architect infrastructure that makes peak traffic boring!
FAQs
What strategies do top VoIP providers use to manage peak call volumes?
Top VoIP providers use predictive capacity planning, real-time QoS monitoring, and intelligent SIP load balancing to manage peak call volumes. These strategies allow them to scale resources on demand and maintain high-quality call experiences even during surges, establishing carrier-grade reliability for enterprise VoIP solutions.
How can businesses monitor QoS in real-time for large-scale VoIP networks?
Businesses can monitor QoS in real-time by implementing detailed infrastructure and per-call metrics such as jitter, packet loss, MOS scores, and network resource usage. Elite VoIP network consulting teams deploy time-series databases and visual dashboards to spot issues before they impact call quality.
How does multi-tenant architecture impact VoIP network scaling?
Multi-tenant VoIP architectures share resources across clients, making isolation and scalability complex. You can include resource allocation, separate monitoring, and burst capacity for high-value clients to prevent competition and contention under peak loads.
How can VoIP providers optimize cost and capacity with auto-scaling?
VoIP providers optimize cost and capacity through auto-scaling based on real-time usage analytics, reducing over-provisioning and responding instantly to demand changes. Intelligent alerting and performance monitoring are also crucial to align resource allocation with business growth and peak activity.
Why do traditional VoIP networks struggle under surge loads?
Traditional VoIP networks struggle because they rely on vertically scaled, monolithic hardware with manual intervention for upgrades. These systems can't adapt quickly enough to sudden spikes in call volume, creating bottlenecks and risking call quality degradation, especially for multi-tenant architectures.