QUICK SUMMARY
Legacy SIP was designed for call signaling, not live intelligence, low latency, or conversational context.
Quick fixes like SIPREC or RTP mirroring struggle at scale, making architectural separation between SIP and AI essential. The future of voice lies in safely extending SIP through modern, AI-aware designs, not replacing it.
“Just plug AI into your SIP stack.”
It’s an attractive idea, and a misleading one.
Teams try it, demos look fine, and then real traffic hits.
→ Latency spikes,
→ AI responses arrive too late,
→ context disappears mid-conversation,
→ and “real-time” quietly turns into “after the call ends.”
And your next question would be, “How can I integrate real-time AI with a legacy SIP system without breaking live calls?” But see, the issue isn’t AI capability. And it isn’t SIP reliability. It’s the gap between SIP signaling systems and real-time intelligence systems.
SIP was built to set up calls, not to support live decision-making. Real-time AI voice, on the other hand, depends on tight latency budgets, continuous access to clean audio streams, and preserved conversational context. Legacy SIP architectures struggle with all three, not because they’re broken, but because they were never designed for this role.
In this blog, we’ll break down where legacy SIP limits real-time AI voice, why common fixes backfire, and how to extend SIP safely without downtime or a full rebuild of your voice stack.
Let us have a look!
How Legacy SIP Architectures Were Designed?
To understand why real-time AI struggles inside traditional voice stacks, you have to look at what SIP was actually built to do. The limitations don’t come from poor implementation; they come from original design assumptions that predate AI by decades.
- SIP was designed for call setup, not cognition
- Signaling is largely stateless, while AI systems are state-dependent
- RTP pipelines prioritize transport efficiency, not insight extraction
SIP’s core responsibility is coordination, establishing sessions, negotiating endpoints, and tearing calls down cleanly. Once the media starts flowing, SIP steps aside. That works well for telephony, but it clashes with AI systems that rely on continuous context and timing throughout a conversation.
In real-time AI voice setups, media flows through SBCs and RTP termination before entering an AI streaming pipeline for speech-to-text, language processing, and text-to-speech. In production, this handoff is typically handled by an AI or a Voicebot connector layer, which consumes live media under strict controls while leaving SIP signaling untouched.
RTP follows the same philosophy: deliver audio reliably and move on. It was never designed to preserve conversational meaning, which is why the AI or Voicebot connector layer exists, to bridge real-time media with AI systems without forcing intelligence into parts of the stack that weren’t built for it.
This is why teams often wonder whether legacy SIP systems can handle AI at scale or are being pushed beyond their original limits.
Reality Check
SIP works exactly as designed!
Real-time AI does too!
The problems start when we expect one to behave like the other.
And that’s exactly where legacy SIP begins to break under real-world AI voice demands.
What actually happens to your calls when AI slows down or fails?
Where Legacy SIP Breaks Real-Time AI
The cracks don’t show up in diagrams. They show up in production.
- Latency Budgets Get Blown Instantly
Real-time AI voice systems need sub-200ms response loops to feel natural. That includes audio capture, streaming, inference, and response.
Legacy SIP call flows plus media relays were never designed for that kind of feedback loop. Each hop adds latency, which degrades VoIP call quality. Every relay adds buffering. And suddenly, “near real-time” turns into awkward pauses and late insights.
Near real-time might be acceptable for analytics dashboards. It’s unacceptable when an AI is supposed to assist a live human conversation.
- Media Forking Is Fragile at Scale
Forking RTP streams sounds reasonable until you do it at scale.
Forked audio isn’t the same as AI-grade audio. Packet loss, jitter, codec mismatches, and duplicated streams don’t just degrade call quality; they directly hurt model accuracy. Speech recognition struggles. Sentiment models misfire. Timing-based insights become unreliable.
What works in a test environment often collapses under real production traffic, especially when teams try to avoid one-way audio and similar other issues when integrating AI.
- Context Is Lost Between Hops
SIP headers were never meant to carry conversational state. They don’t know who’s speaking, what’s already been said, or why a pause matters.
AI systems, on the other hand, depend on session continuity. They need to know what happened five seconds ago to interpret what’s happening now. SIP never promised that continuity, and retrofitting it is harder than it looks.
- Security Models Were Never AI-Aware
Opening SIP ports is not the same as opening live media streams to AI systems.
The moment you expose audio to external processors, you introduce new attack surfaces, media interception, unauthorized access, and compliance (HIPAA, GDPR…) violations. Legacy SIP security models weren’t built to govern AI access, audit model behavior, or control data lifecycles.
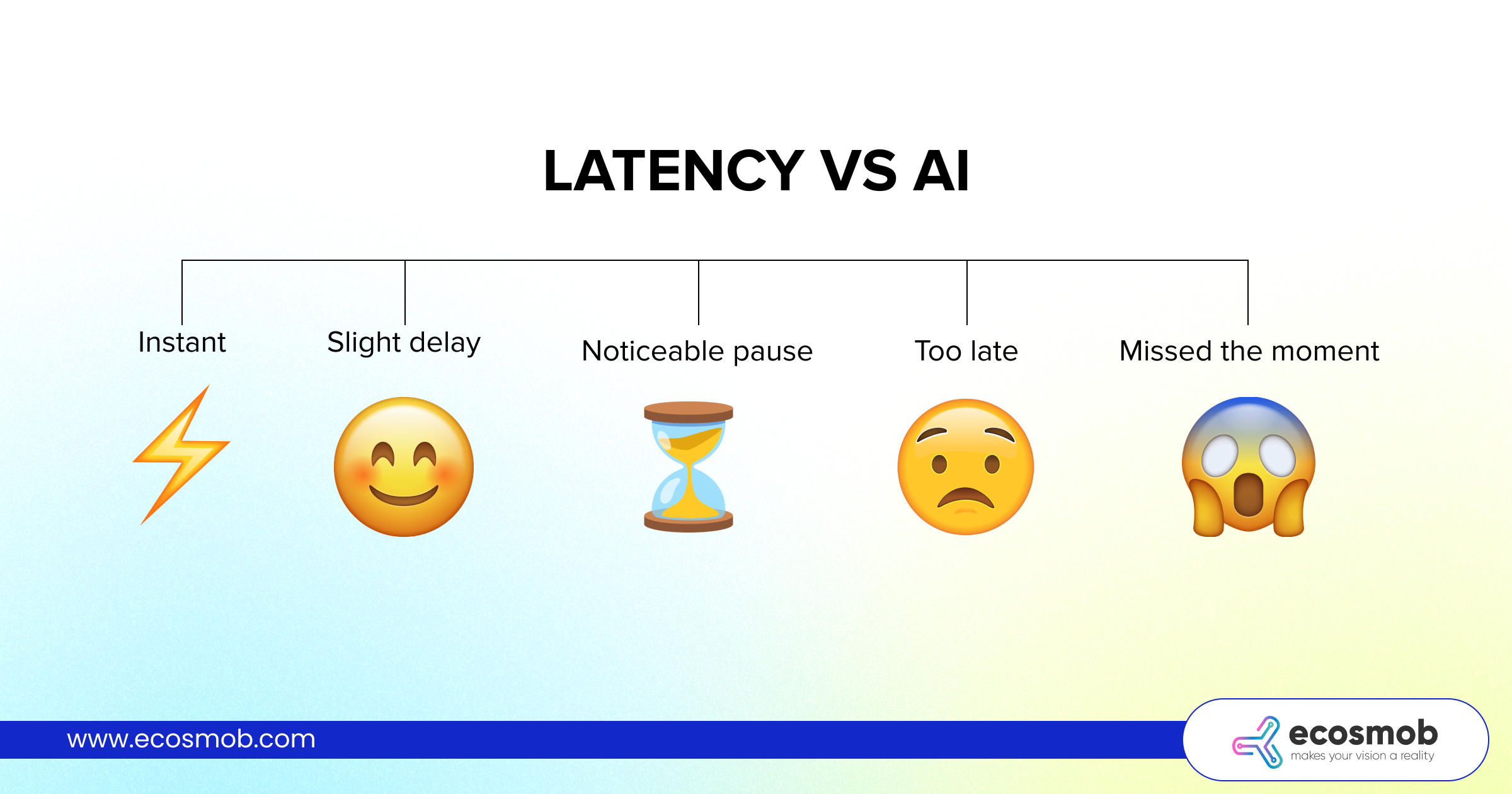 (As latency increases, AI goes from helpful to awkward to useless.)
(As latency increases, AI goes from helpful to awkward to useless.)
This is where “it works” quietly turns into “it’s risky.”
Why Common SIP AI-Integration Approaches Fail in Production
When teams try to close the gap between SIP and real-time AI quickly, they usually reach for interim integration techniques. And in a lab or a limited pilot, those approaches can seem fine. But the moment you care about tight latency, real traffic volumes, or compliance, the cracks start showing.
- SIP recording solutions are often used as a stand-in for real-time feeds, even though they were built for recording and replay, not for feeding low-latency AI models that require audio in real time.
- Media duplication creates additional audio paths that appear harmless at first, but they rarely remain synchronized and almost never behave predictably as the load increases.
- RTP stream mirroring gives AI access to raw audio without preserving conversational timing, speaker context, or the access controls you need when AI is part of a live call.
These techniques can help demonstrate that an idea is feasible, but they sit outside the assumptions on which real-time AI voice systems are built. Over time, this shows up as delayed insights, unreliable model behavior, and governance headaches, especially once AI starts influencing live conversations rather than just observing them.
At this point, the limitation isn’t tooling or models, it’s the absence of an architecture built for real-time AI interaction.
The SIP and AI Duo
SIP: “I’ll set up the call.”
AI: “I need context, timing, and intent… right now.”
What Real-Time AI Voice Actually Needs Architecturally
Once you move past quick fixes and experiments, the requirements for real-time AI voice become pretty clear. This isn’t about adding one more service to your SIP stack. It’s about supporting an interaction model in which voice and intelligence must work together while the conversation is ongoing.
- Persistent, Low-Latency Access to Live Media
If AI is expected to react in real time, it needs continuous access to live audio, not recordings, not delayed forks, and not buffered segments. Even small delays add up fast when capture, inference, and response all sit on the critical path. Practically speaking, this means AI needs a predictable, low-latency path to media that doesn’t disappear or degrade once traffic increases.
- Event-Driven, Bi-Directional Streaming, Not Passive Listening
Letting AI “listen in” is easy. Letting it respond at the right moment is much harder. Real-time voice use cases depend on event-driven, bidirectional streams, where AI can emit insights as events rather than waiting for audio chunks to finish. Without this, AI stays stuck in observer mode and can’t assist, adapt, or intervene when timing actually matters.
- Session Context That AI Can Actually Use
AI doesn’t just process audio. It also processes conversations. That means knowing who’s speaking, what’s already been said, how long a pause lasts, and whether it’s meaningful. SIP headers were never meant to carry that kind of evolving context. If the architecture doesn’t preserve session continuity explicitly, the AI ends up guessing, and guesses don’t add up to SIP scalability.
- Deterministic Failure Handling, Not Silent Degradation
In live voice systems, something will eventually go wrong: packets will drop, models will stall, or networks will hiccup. The key is that the AI needs to know when that happens. If audio is incomplete or delayed, the system must clearly surface it. Otherwise, the AI continues to make decisions based on partial information, and trust in automation erodes quickly.
When you put all of this together, one thing becomes obvious: real-time AI voice can’t be treated as an afterthought in existing SIP media paths.
It needs architectural support that treats time, context, and reliability as first-class concerns.
LOL
SIP had one job.
Real-time AI gave it three more.
Are you debugging AI issues, or SIP issues pretending to be AI? If not…
SIP Modernizing Architectures to Support Real-Time AI Voice
This is where most architectures go wrong, and where they can go right.
Legacy SIP can work with real-time AI, but only if you stop asking it to do jobs it was never meant to do. The trick isn’t rebuilding your voice stack. It’s knowing exactly where to draw the line between call handling and intelligence, and keeping that line clean.
- Keep Call Control and AI Processing Separate
SIP already does call control extremely well. There’s no reason to drag AI into that path.
- Let SIP handle call setup, routing, and teardown
- Run AI outside the signaling flow
- Make sure a slow or failed AI never affects the call
When AI logic sits directly inside call flows, even small delays start to matter. A model taking a few hundred milliseconds too long suddenly becomes a bad call experience. By keeping AI separate, calls stay stable and predictable, while AI can evolve independently. This separation is what makes SIP AI integration workable at scale.
Once you stop AI from touching call control, the next problem is how it hears the conversation at all.
- Give AI a Clean, Controlled Way to Hear Audio
AI needs access to live audio, but it doesn’t need to live inside your media pipeline.
- Expose audio through a dedicated access point
- Keep carrier-grade voice processing isolated
- Control who can access audio, when, and how
A controlled media ingress layer allows AI to consume live audio without interfering with core voice flows. By routing access through a SIP ingress controller, media delivery remains stable and predictable, while AI systems get the quality they need.
But even with clean audio, AI still shouldn’t be allowed to slow the conversation down.
- Let AI Assist the Call and Not Hold It Hostage
AI works best when it can observe and respond, not when it blocks progress.
- Send audio and events to AI asynchronously
- Feed insights back without pausing the call
- Allow calls to continue even if AI lags or drops
When AI is event-driven, it can help in real time without becoming a dependency. If a model stumbles, the conversation doesn’t. That’s the balance SIP modernization needs, keeping human conversations smooth while still unlocking real-time intelligence.
Don’t Do This!
❌ Don’t put AI in the call path as it adds latency and breaks calls.
❌ Don’t fake real-time with recordings or RTP mirrors because they fail at scale.
❌ Don’t expose live audio without hard controls, as that’s a silent risk.
What “AI-Ready SIP” Should Mean?
True Artificial Intelligence readiness isn’t a checkbox.✔️
Buyers should demand clear criteria: how media is accessed, how latency is controlled, how context is preserved, and how failures are isolated. Architecture diagrams that blur AI into the SIP core are red flags.
And one simple question exposes fake readiness fast: What happens to SIP under high AI traffic?
If the answer isn’t immediate and deterministic, the architecture isn’t ready.
After going through all of this, the end picture starts to feel pretty clear.
How far can your SIP architecture stretch before it snaps?
The Final Thought?
SIP is still reliable, but it was never meant to carry real-time AI on its own.
The future of voice isn’t about replacing SIP. It’s about outgrowing its limits safely, with architectures that respect what SIP does well while enabling what modern AI demands.
This is where Ecosmob helps. Through focused SIP modernization strategies, secure media ingress designs, and production-grade AI SIP connector solutions, Ecosmob enables real-time AI voice use cases without destabilizing existing voice infrastructure. Their approach makes SIP AI integration practical, scalable, and compliant without forcing a rewrite of existing code.
Because the smartest systems don’t throw away the past, they extend it, carefully, deliberately, and with eyes wide open!
FAQs
Why can’t legacy SIP architectures support real-time AI voice out of the box?
Because SIP was built to set up and manage calls, not to support live decision-making. Real-time AI needs low latency, continuous audio access, and conversational context, all of which sit outside SIP’s original design assumptions. The friction you feel isn’t a bug; it’s an architectural mismatch.
What exactly breaks when AI is added directly into SIP call flows?
Latency, reliability, and failure isolation. Even small AI delays can impact live calls, and if AI fails inline, it can take the call down with it. SIP call flows were never meant to wait on inference engines, which is why direct integration causes problems at scale.
Is RTP media forking enough for AI use cases like transcription or sentiment analysis?
Not reliably. Forked RTP streams often suffer from jitter, packet loss, and timing issues that don’t matter much for human listeners but significantly impact AI accuracy. What works in a lab setup usually degrades fast under real traffic.
Can SIPREC be used safely for real-time AI?
SIPREC was designed for recording, not live intelligence. Using it for real-time AI is a workaround at best and a risk at worst. It introduces delays, compliance concerns, and scaling issues, especially when treated as a primary AI audio source.
Does enabling AI mean replacing the existing SIP infrastructure?
No. SIP still does its job well. The goal is SIP modernization, not replacement, keeping SIP for call control while extending the architecture to enable AI to operate alongside it without interfering. Done right, this preserves stability while unlocking new capabilities.





![SIP Protocol [SIP Signalling]](https://cd3e0a26.delivery.rocketcdn.me/wp-content/uploads/2024/12/Blog-79.jpg)