QUICK SUMMARY
This blog explains why strong AI metrics don’t always translate into smooth customer conversations, highlighting the critical role of voice infrastructure. It covers what traditional dashboards measure, the network factors they miss, the impact on ROI, essential voice quality metrics, and best practices for building infrastructure that supports reliable conversational AI.
“The customer is at the center of everything we do.” — Satya Nadella
And if that’s true, then every interaction, especially those handled by conversational AI, should feel smooth and responsive. After all, customers may not see the technology behind the conversation, but they do remember how it made them feel. And the moment a conversation sounds delayed, interrupted, or unnatural, trust starts to erode. Yet most conversational AI metrics fail to capture these critical moments—the hesitations, the unnatural pauses, the missed emotional cues that break trust when proper voice infrastructure isn’t supporting the system.
Now imagine calling an AI-powered support line. You ask a simple question, but the response takes a moment too long. You speak again, the assistant interrupts, and within seconds you’re repeating yourself, trying to get the conversation back on track.
The rhythm is gone.
Within seconds, the conversation feels frustrating, even though the system itself may be highly advanced.
But here’s the catch: internally, performance dashboards might still look strong.
Intent accuracy is high. Containment rates look promising. Response times seem within range. On dashboards, AI Voicebot solutions appear to be performing exactly as designed. But when the voice layer lacks stability, these metrics fail to capture what customers are actually experiencing.
Conversational AI depends on real-time voice infrastructure, and when that foundation is weak, even the smartest models can fall apart.
What looks like an AI problem is often an infrastructure gap, and understanding the difference is key to delivering conversations that truly work.
Key Conversational AI Metrics And What They Actually Measure
Before diving into what often goes unnoticed, it’s worth looking at what organizations typically track, especially as evolving communication trends continue to shape how businesses evaluate customer interactions. Traditional conversational AI metrics primarily assess how accurately the model understands user input and how efficiently it delivers responses.
Typical dashboards surface indicators such as:
- Intent accuracy – whether the system correctly understands what the caller needs
- Entity extraction – how reliably it captures critical details like names, dates, or account information
- NLU confidence scores – the probability assigned to the model’s interpretation
- Containment rate – how often the AI resolves queries without agent intervention
- Response time – the speed at which replies are generated
These metrics matter because they validate that the AI is functioning as designed. Strong scores often signal readiness for scale, and naturally, leadership teams rely on them to gauge success.
However, these measurements primarily reflect model behavior. They confirm that the intelligence works, but not necessarily that the conversation feels seamless to the customer.
And, this is where many evaluations stop short, and where a deeper operational layer begins to influence outcomes.
Not sure your voice layer is as strong as your AI? Let’s take a look.
What is Carrier-Grade Voice Infrastructure?
Every AI-driven conversation travels through a real-time voice delivery environment before it is processed, typically through a voicebot connector that bridges the AI platform with enterprise telephony systems. This carrier-grade voice infrastructure quietly determines whether speech reaches the system clearly, consistently, and fast enough to support natural dialogue.
When this foundation is engineered well, conversations flow without effort. When it isn’t, friction appears almost immediately.
Several infrastructure variables shape that experience:
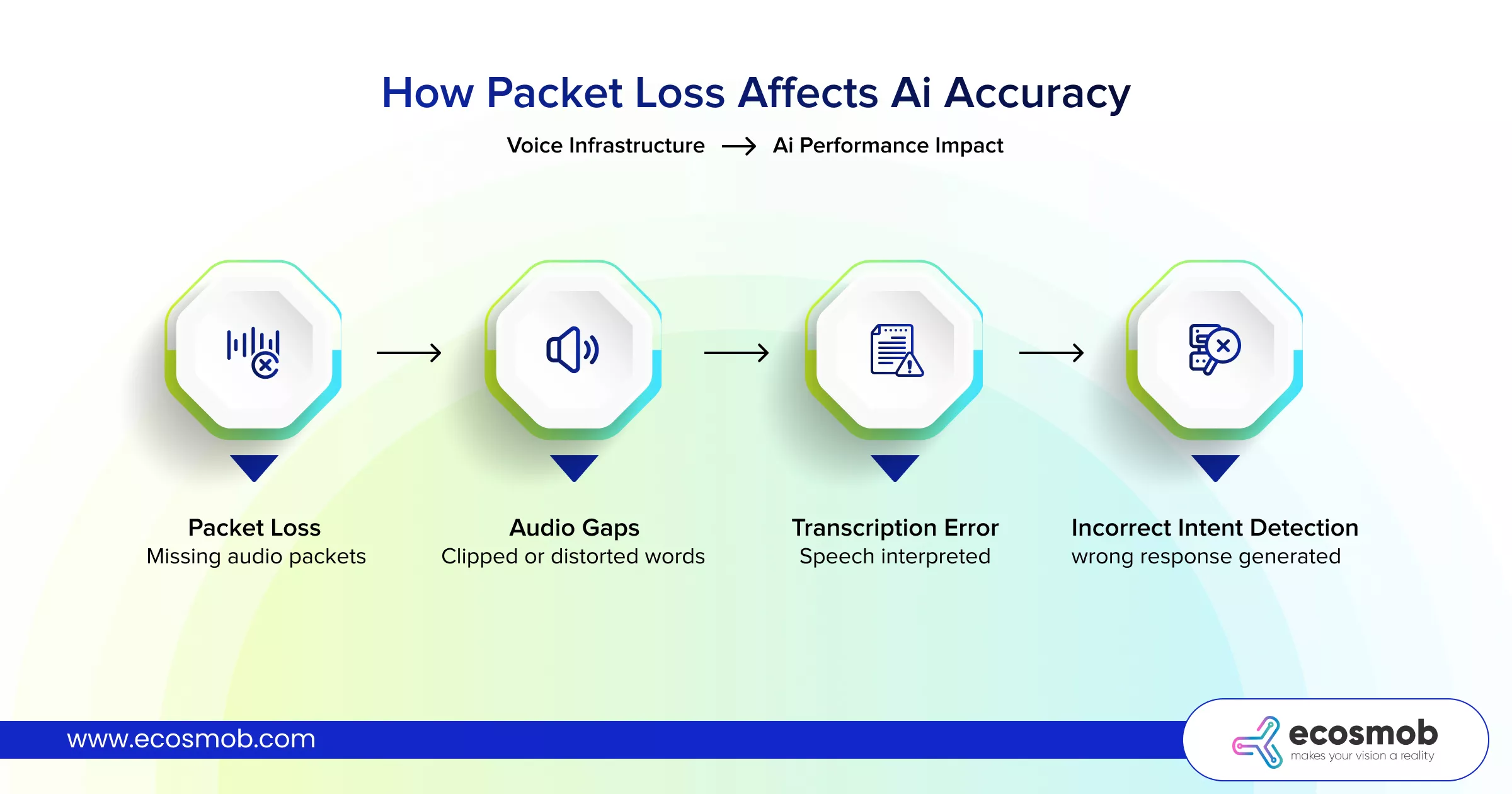
Packet loss – Missing audio fragments can remove syllables or entire words, forcing speech engines to infer meaning from incomplete input.
Jitter – Irregular packet timing creates uneven audio, disrupting conversational rhythm and making speech harder to interpret.
Latency – Delays, even brief ones, can cause responses to land a moment too late, altering the pace users instinctively expect.
Codec selection – Compression decisions directly affect audio detail. Reduced fidelity may strip away tonal cues that recognition models depend on.
Network routing quality – Long or inefficient paths increase exposure to degradation before audio reaches your platform.
These conditions, including jitter and latency, rarely appear on AI dashboards, yet they heavily influence how well the system performs in real-world environments. What may look like a modeling issue often originates earlier, in how the audio was transported.
Recognizing this distinction helps organizations focus their optimization efforts where they will have the greatest effect.
How Voice Infrastructure Directly Impacts Conversational AI Performance and ROI
 Infrastructure quality is not just a technical concern, it has measurable financial consequences.
Infrastructure quality is not just a technical concern, it has measurable financial consequences.
Consider how quickly small disruptions compound:
What starts as a network inconsistency can ripple outward until the interaction fails to resolve the customer’s need.
Other patterns follow a similar trajectory:
- Jitter can fragment speech, increasing recognition difficulty
- Latency can disturb conversational timing, making interactions feel less intuitive
- Low-fidelity codecs can blur acoustic signals that models rely on for precision
These technical shifts translate directly into business outcomes.
A marginal rise in packet loss can noticeably lower satisfaction scores. As experience quality declines, containment weakens, escalations increase, and operational costs climb.
Correcting infrastructure after deployment is also significantly more expensive than preparing it in advance. Many organizations discover this only after investing heavily in model tuning, when the real constraint lies beneath the AI layer.
Voice quality issues further influence:
- Agent workload through higher transfer rates
- Call durations due to repeated clarification
- Customer adoption when early interactions fail to build confidence
Another important consideration: AI models are typically trained on clean audio datasets. When deployed on degraded networks, performance naturally diverges from lab conditions, not because the model is flawed, but because the environment has changed.
For organizations evaluating conversational AI ROI, infrastructure stability often becomes a decisive multiplier.
If conversations are breaking somewhere, we’ll help you find where.
Voice Quality Metrics You Should Be Tracking for Conversational AI
If you’re investing in conversational AI, you’re already tracking intent accuracy, containment, and confidence scores. That’s good. But if you’re not tracking voice quality alongside them, you’re only seeing part of the performance picture.
Let’s talk about the metrics that actually determine how clean the audio reaching your AI really is.
1. MOS (Mean Opinion Score)
MOS is a standardized way of measuring perceived call quality on a scale from 1 to 5.
- 4.3–5.0 → Excellent, near natural conversation
- 3.6–4.2 → Good, minor imperfections
- 3.1–3.5 → Noticeable degradation
- Below 3.0 → Frustrating to listen to
For conversational AI, you generally want MOS above 4.0. Once it dips below that, speech recognition accuracy can start slipping, even if your model hasn’t changed at all.
The key point? If MOS drops, your AI accuracy will likely follow.
2. RTP Metrics (Packet Loss, Jitter, Latency)
These are the real-time health indicators of voice transport.
Packet Loss Rate
Anything above 1% begins affecting transcription reliability. At 2–3%, users may start repeating themselves. Beyond that, misclassification becomes common.
Jitter
Should ideally stay under 30 ms. Higher jitter causes audio chunks to arrive unevenly, making speech engines struggle with flow.
Latency
To maintain natural conversation rhythm, latency typically needs to stay under 150 ms round-trip. Beyond that, users feel the delay, and conversation timing starts breaking down.
You don’t need perfect numbers. You need stable numbers.
Consistency matters more than spikes of “almost perfect.”
3. Audio Sampling Rate & Bit Depth
Most AI speech models perform best with 16 kHz or higher sampling rates.
If you’re compressing audio too aggressively to save bandwidth, you might unintentionally remove frequencies that help the model distinguish similar words.
For example:
“Balance” vs. “Valence”
“Four” vs. “For”
Small frequency differences matter.
Lower fidelity doesn’t just affect how it sounds to humans, it affects how accurately your AI interprets it.
4. Echo & Background Noise Levels
Humans can mentally filter out background noise. Machines aren’t as forgiving.
Persistent echo, overlapping speech, or noisy routing environments increase transcription uncertainty. That uncertainty shows up as lower NLU confidence, but the root cause isn’t the model. It’s the signal quality.
If your AI confidence score drops during peak hours, don’t immediately retrain the model. Check the audio conditions first.
5. Voice Activity Detection (VAD) Accuracy
VAD determines when someone has finished speaking.
If VAD misfires:
- The AI interrupts users.
- The system waits too long to respond.
- Conversations feel awkward or robotic.
When users say, “It keeps cutting me off,” that’s often a VAD tuning issue, not an intelligence issue.
How to Actually Monitor These?
You don’t need a completely new analytics stack. Most SIP platforms, SBCs, and media servers already expose RTP statistics. The problem is they’re rarely tied to AI dashboards.
The smarter approach is integration:
- Correlate packet loss spikes with drops in intent accuracy.
- Compare MOS trends against containment dips.
- Monitor and fix latency alongside customer satisfaction metrics.
When voice metrics and AI metrics are viewed together, troubleshooting becomes faster and far less expensive.
Best Practices for Building Voice Infrastructure for Conversational AI
If conversational AI, especially a conversational AI IVR, is part of your long-term customer strategy, your voice infrastructure shouldn’t be an afterthought.
Let’s break this down practically.
1. SIP Trunk Quality Requirements
Not all SIP trunks are equal.
Low-cost providers may route traffic across unpredictable paths, increasing latency and packet loss. For AI use cases, you need:
- Stable routing
- Low packet loss guarantees
- SLA-backed uptime
- Consistent codec negotiation
If your SIP layer fluctuates, everything above it becomes unstable.
Think of SIP quality as the entrance gate to your AI. If traffic is messy there, it won’t clean itself up downstream.
2. Media Server Specifications
Your media servers handle encoding, decoding, and real-time processing. If they’re underpowered:
- Latency increases during traffic spikes
- Transcription queues build up
- Conversation timing shifts
Ensure:
- CPU headroom for peak concurrency
- Scalable architecture (horizontal scaling preferred)
- Dedicated processing for AI traffic when possible
Overprovisioning slightly is cheaper than losing customer trust.
3. Network QoS Configuration
Voice packets must be prioritized over general data traffic.
Without proper QoS:
- A file upload can interfere with a live call.
- Congestion creates jitter and delay.
- Performance becomes inconsistent.
Mark voice traffic appropriately and ensure switches and routers honor those markings across the path.
If voice isn’t prioritized, your AI is competing with everything else on the network.
4. Optimal Codec Selection for AI
Some codecs save bandwidth but sacrifice clarity.
For conversational AI, clarity usually matters more than compression. Wideband codecs (like G.722 or Opus in high-quality modes) preserve frequency ranges that improve speech recognition.
This isn’t about what “sounds fine.” It’s about what feeds your acoustic model clean data.
Test codecs not just for human listening, but for transcription accuracy.
5. Geographic Routing & Edge Deployment
Distance introduces latency. If your AI processing is centralized in one region but users are global, the round-trip delay increases.
Edge deployments or regional media nodes reduce latency and improve responsiveness.
The closer your processing is to the caller, the more natural the conversation feels.
6. Architecture Patterns for AI-Optimized Voice
AI-ready architectures typically:
- Separate control and media layers
- Enable dynamic routing
- Use session border controllers with intelligent traffic management
- Provide observability at both network and application levels
This separation ensures that scaling AI workloads doesn’t destabilize media transport.
Design for elasticity. Real-time traffic fluctuates.
7. Test Before You Deploy
This is where many teams cut corners.
Before scaling AI live:
- Simulate peak concurrent calls
- Inject controlled packet loss
- Test jitter scenarios
- Evaluate transcription under degraded conditions
- Monitor containment and intent accuracy during stress
If performance collapses under stress testing, it will collapse in production, just more expensively.
Testing infrastructure before AI rollout costs a fraction of fixing problems afterward.
Great AI needs a voice layer that can keep up. Is yours ready?
The Bigger Picture?
Here’s what it comes down to:
Conversational AI, a market projected to reach $49.8 billion by 2031, doesn’t operate in isolation. It sits on top of a real-time delivery system. If that system is unstable, optimization efforts higher up the stack become inefficient.
You can retrain models endlessly. But if packet loss is high or latency is inconsistent, performance gains will plateau.
Strong infrastructure doesn’t just support AI, it unlocks its full capability.
And that’s where organizations with deep expertise in carrier-grade voice infrastructure, like Ecosmob, bring value. Building AI-ready communication environments requires both networking depth and AI awareness.
Because at the end of the day, conversational AI succeeds when the intelligence is sharp, and the signal carrying it is just as strong.
FAQs
Why does conversational AI work in testing but struggle in production?
Testing happens in controlled conditions with clean audio and stable networks. In production, real-world factors like background noise, packet loss, jitter, and latency affect how speech is transmitted, and that can quickly expose infrastructure gaps.
Why do my AI metrics look good but customers still complain?
Most dashboards measure model performance, not audio quality. If speech reaches the AI distorted or delayed, the system may still appear accurate while customers experience interruptions or misunderstandings.
How does voice quality affect AI accuracy?
Clear audio leads to accurate transcription, which supports correct intent detection. When voice quality drops, errors increase, creating a ripple effect across the entire interaction.
How does packet loss affect speech recognition?
Packet loss removes parts of the audio stream, forcing the system to interpret incomplete speech. Even small losses can increase transcription errors and result in incorrect responses.
What voice infrastructure is required for reliable conversational AI?
Stable SIP connectivity, low packet loss, controlled jitter, minimal latency, optimized codecs, and proper QoS are essential. Strong infrastructure ensures the AI hears users clearly and responds naturally.